Expanding WebLS to Support a Breast Cancer Decision
Guide
[This article was originally published in PC AI magazine, Volume 12,
Number 2 Mar/Apr 98. The
magazine can be reached at PC AI, 3310 West Bell Rd., Suite 119,
Phoenix AZ, USA 85023 Tel:
(602) 971-1869, FAX: (602) 971-2321, E-Mail: info@pcai.com, Web:
http://www.pcai.com]
by
Mary Kroening, Amzi! inc.
Dr. Sabina Robinson, SAIC
Dr. Fred Hegge, U.S. Army Medical Research and Materiel Command
Background
In 1996, the WebLS tool was built in order to provide a simple inference
engine for web-based advisors and problem solvers [Sehmi, 96][Kroening,
96]. The initial focus of this project was to provide a tool that webmasters
(as opposed to AI programmers) could use to build small to medium sized
expert systems. The expert systems ask the user to enter the values for
facts using web forms, then apply if-then rules to select 'chunks' of HTML
to include in an output document organized by an outline.
The challenges WebLS faced in its initial implementation were:
-
Maintaining the state of the inference engine for each user across multiple
invocations of the shell via web forms on a multi-user server.
-
Grouping questions together, instead of the traditional one-at-a-time,
to conserve both network bandwidth and user's patience.
-
Integrate expert system inputs and outputs with existing web resources
(e.g. pictures, documents, other sites).
-
Use an intuitive and easy-to-maintain syntax for the rules, along with
debugging tools that ease the development and maintenance processes.
These challenges were met by having WebLS run as a CGI script while maintaining
state in temporary files (this has since been replaced by hidden form fields).
The displayable content of the expert system's logic-base is all maintained
in HTML format, thereby allowing the use of any HTML tags for formatting
the display and including content. A means was provided to specify which
questions are related and hence should be asked together. And, a simple
if-then syntax and backward chaining engine was implemented using Prolog
and its operators [Merritt, 96].
This past year, we have expanded WebLS to support a large web-based
breast cancer decision guide, called BCPath, with the additional requirement
that the knowledge base is both maintainable and verifiable by experts
in the field. This work has led to new insights in solving some of the
original challenges as well as introducing many new ones. This paper documents
the solutions and their implications.
Design Goals and Requirements
The goals and requirements of the BCPath system are:
-
To provide information to military and non-military breast cancer patients
and their families based on the patient's diagnosis and life situation.
It is important to note that the decision guide is an information tool
to assist in decision making, it does not dispense medical advice or display
recommended courses of action. Decision making support is especially important
after the initial diagnosis is made as the patient is required to make
a number of far-reaching and difficult decisions while under a lot of stress,
which adversely affects decision making ability.
-
Provide information for all the steps along the breast cancer pathway,
from prevention, screening and diagnosis to health maintenance and end-of-life
issues.
-
Encode the knowledge in a form that allows for it to be readily edited,
verified (vetted), maintained and re-used.
The BCPath system consists of a logic-base and the
WebLS shell that executes it.
Logic-Base Architecture
The BCPath application stressed the original WebLS architecture in
two directions. One was size and the other was the need to maintain accurate,
verified information in the knowledge base.
The size issue was addressed by the addition of module support. Modules
let a large application, like BCPath, be subdivided into smaller, more
manageable chunks.
The need for accurate, verified information was addressed by using a
variation on Arden Logic Modules for the primary knowledge representation.
Arden is a tool for knowledge representation that was designed for critical
medical applications, and that is often used in event-driven real-time
medical systems. For BCPath, the Arden knowledge representation was enhanced
to support the more passive inference rules required for a medical decision
support system and the web.
Modules for Each Step on the Path
The logic-base for breast cancer decision making is very large, reasonably
complex and constantly changing. Breast cancer research provides new information
on a regular basis, and oftentimes leads to changes in medical practice
standards. To build a manageable system, the BCPath logic-base is structured
into a series of modules. Each module represents one step on the path.
They are:
-
Risk Factors & Prevention
-
Early Detection
-
Diagnosis & Prognosis
-
Treatment
-
Clinical Trials
-
Psychosocial Issues (Coping)
-
Symptom Management
-
Rehabilitation & Health Maintenance (Survivorship)
-
Military-Specific Issues (BCPath is funded by the Department of Defense)
-
Practitioner & Facility Options
-
End of Life (Advanced Cancer)
The user is not required to proceed through the modules in order, nor is
each module completely independent. The system keeps all the user-entered
facts (age, biopsy type(s), cancer type(s), clinical stage, etc.) as global
data, and the knowledge engineer can create global rules, such as those
that deduce the clinical stage of the cancer from the attributes of the
tumor(s).
As of this writing the Diagnosis & Prognosis and Treatment modules
are nearing completion. They were written first because Treatment is the
largest and most complex module, and it heavily depends on Diagnosis &
Prognosis.
Using Arden ALMs to Build Modules
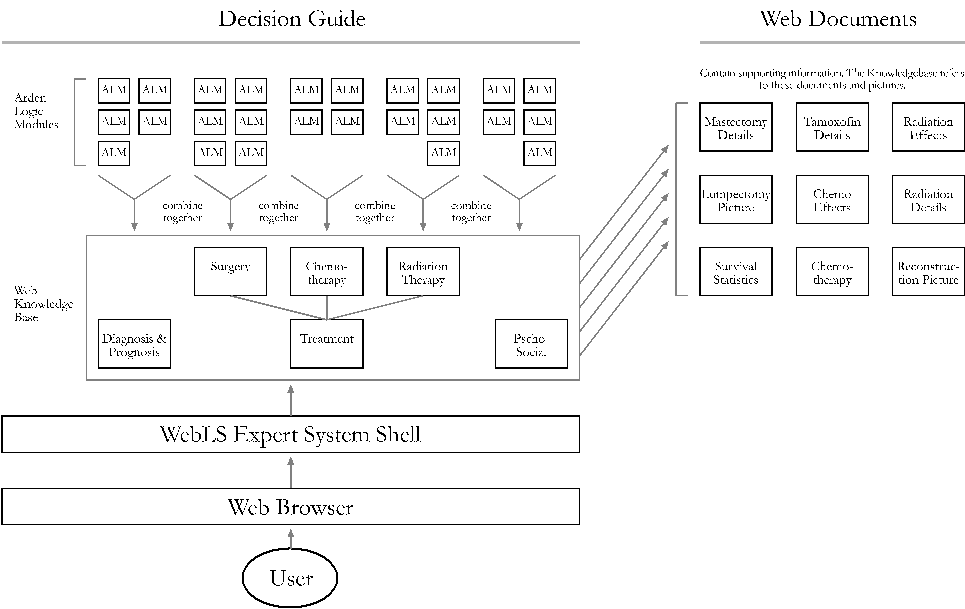
Figure 1: The breast cancer knowledgebase is comprised of a large number
of small pieces of knowledge called ALMs. These ALMs are grouped by subject
area into modules, which are then executed by the WebLS shell. The ALMs
are supported by conventional web documents and pictures.
Each BCPath module is composed of a number of smaller units called Arden
Logic Modules (ALMs). An ALM is a frame-based representation of a single
piece of knowledge where the more critical slots contain either an inference
rule, questions to be posed to the user or chunks of answer text to be
displayed if appropriate. Unlike knowledge representation structures designed
just with the inference engine in mind, ALMs also contain a large number
of slots for human use. These slots describe the person and organization
who wrote the ALM, the date and version of this particular instance, and
the medical references used both for writing the ALM and supporting its
knowledge. It is these slots which are used in the human process of writing,
editing and vetting each ALM to ensure it is readable, consistent and correct
according to medical standards.
Figure 1 shows the overall relationship between the key components of
the BCPath system. ALMs are stored and maintained in a conventional file/directory
structure, where each subdirectory contains the ALMs for a single BCPath
module. A preprocessor then reads all of the ALMs in a module and creates
a WebLS module file from it. The WebLS modules are then made available
to WebLS, running on a Web server, and are available for interaction with
a user.
Sample ALM
Below is a sample ALM. There are three frames: maintenance, library and
knowledge. The last frame contains the heart of the ALM as far as the WebLS
inference engine is concerned. Parts of the first two frames are used as
well, but only to provide background information to the user when asked.
This particular ALM contains a rule that concludes whether or not radiation
therapy is recommended and the HTML text that will be displayed to the
user if this particular rule is activated.
maintenance:
title: International Consensus Panel: Adjuvant Therapy Recommendations;;
filename: ra_rec_st_gallen_consensus_chemotherapy_1;;
version: 1.00;;
institution: SAIC;;
author: Kim Francis;;
specialist: Sabina Robinson;;
date: 1997-07-12;;
validation: testing;;
library:
purpose: To indicate under which conditions chemotherapy is generally recommended. ;;
explanation: According to an international panel of breast cancer experts, chemotherapy is recommended for premenopausal women who have
node positive breast cancer and are not experiencing a recurrence. ;;
keywords: chemotherapy, axillary nodes;;
citations:
Goldhirsch A; Wood WC; Senn H-J; et al. Meeting highlights: International
consensus panel on the treatment of primary breast cancer. Journal of the
National Cancer Institute 1995 87:1441-1445. ;;
links: ;;
knowledge:
type: rule_answer;;
priority: 23;;
logic: {prolog:
if recurrence = no and menopausal = pre
and breast_cancer = node_positive
then recommended = rec_st_gallen_consensus_chemotherapy_1};;
name: rec_st_gallen_consensus_chemotherapy_1;;
applies:
This applies to node positive breast cancer in premenopausal women. </P>;;
text:
According to the treatment recommendations developed by the
<A HREF="/gloss.html#consensuspanel">consensus panel</A>
at the 5th International Conference on
<A HREF="/gloss.html#adjuvanttherapies">Adjuvant Therapy</A>
of Primary Breast Cancer held in St. Gallen, Switzerland, in March 1995,
chemotherapy is considered appropriate treatment for premenopausal patients with node-
positive breast cancer. </P>;;
end:
|
Figure 2: This sample ALM contains a rule that informs users on
the use of chemotherapy in treatment of node-positive breast cancer in
premenopausal women. The ALM is divided into 3 sections. 'Maintenance'
describes the title, author and version information. 'Library' provides
a description, keywords and citations. 'Knowledge' is the computer executable
rule and HTML text to display when the rule succeeds.
Types of ALMs
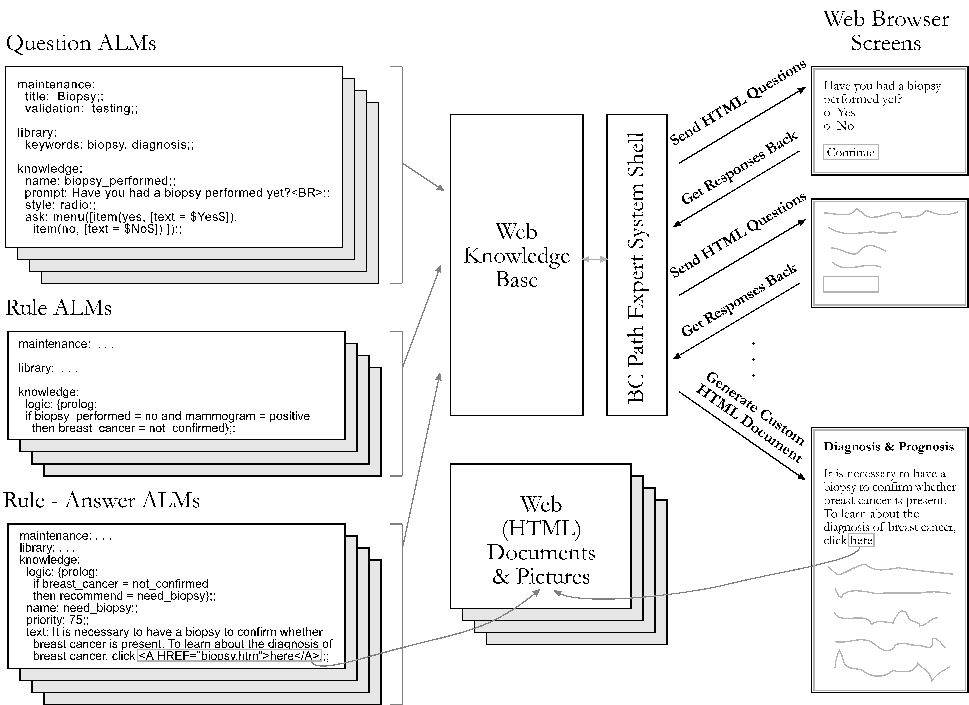
Figure 3: There are three types of ALMs in the decision guide. Question
ALMs describe how to ask the user a question, and typically define a prompt
and menu. Rule ALMs represent pure knowledge that can be inferenced over.
Rule-Answer ALMs represent information that is presented to the user as
part of the output document.
There are three types of ALMs in BCPath. Question ALMs describe how to
ask the user for a value for a fact. Rule ALMs deduce facts from other
facts. Together these two represent the ways to get facts into the system.
The third type of ALM, Rule-Answer, (like the sample above) has one or
more rules and some HTML text to output. When the conditions in the rule
are matched, the corresponding HTML 'chunk' is included in the custom-generated
document. Most of the ALMs in the system are Rule-Answers.
Figure 3 presents another view of the relationship between ALMs and
the WebLS inference engine.
Organizing ALMs by Topic
The result of a consultation with WebLS is a custom-generated document
organized according to an outline. The document typically contains 10-100
'chunks' of HTML from the Rule-Answer ALMs. Because this can be a large
amount of information, the answers are organized into sections, where each
section corresponds to a goal from the then-side of the rules (e.g. then
goal = value). The goals/sections for BCPath are as follows:
-
General: General information
-
Known: This is what is known
-
Recommended: This is what is generally recommended
-
Inappropriate: This is what is generally considered inappropriate
-
Controversial: Areas in which there is controversy
-
Similar: Areas in which the available options are similar
-
Different: Areas in which the available options are different
-
Others: What others do in a similar situation
-
Research: Areas in which research is being conducted
-
Additional: Additional information.
Within an outline section, the answers are ordered according to a priority
number specified in each ALM. Fine control is provided over the document's
appearance by providing headers, footers and answer separators for each
section.
Building the Logic-Base
Written by the Domain Expert
The rule syntax and inferencing semantics in WebLS were kept as simple
as possible so that systems could be written by the domain expert. This
was the case with BCPath-the logic-base was written entirely by a pharmacologist,
who had no prior experience with programming or expert systems, and only
user-level knowledge of PCs, although a programmer was available for design
consultations.
The development process was aided considerably by two features. First,
automatic consistency checking of the logic-base was added to the system.
Second, a full debugging trace was available at all times.
Automatic Consistency Checking
When WebLS loads a logic-base (in debug mode) a number of consistency checks
are performed. These ensure:
-
Each condition refers to a question fact or the result of another rule
-
Each fact value in a condition is legimate
-
Answers referenced on the then-side are defined
-
There are no 'orphan' questions or answers
Using Full Traces for Debugging
Each time WebLS is invoked, a full trace of its activity is produced (in
debug mode). This trace shows the values of all user-entered facts, and
the complete inferencing activity: the checking of every rule and every
value in every rule. This allows the logic-base developer to understand
exactly why and when questions and answers are presented.
Running the Logic-Base with WebLS
WebLS is a CGI script, written in C and Amzi!Ò Prolog, which runs
on the Web server using Amzi!'s Logic ServerÔ interface. Provisions
are being made to also run WebLS using the faster NSAPI and ISAPI interfaces.
The operation of the script is controlled by a main module that defines
all the modules in the system, plus settings for all sorts of global parameters.
Compiling ALMs into WebLS Modules
WebLS logic-bases are actually Amzi! Prolog source files that utilize Prolog
operators (if, then, etc.) to get a readable rule syntax. ALMs are not
Prolog source files. There is a translator that takes a group of ALMs and
compiles them together into a single module. WebLS can execute the module
either in source form, or as a compiled Prolog module (for better performance).
How the Inference Engine Works
The inference engine in WebLS tries to prove every rule. It starts by outputting
a fixed set of questions that the user responds to. In essence, this 'primes'
the inference engine with a beginning set of facts. Using those facts,
the WebLS engine proceeds through the goal list trying to prove every rule
for each goal. If it encounters a rule that could be true (a hypothesis)
if additional facts were known, then those facts are added onto a list
of questions to ask next.
This process continues until all the rules have been proven or disproven.
Then an output document is assembled from the 'chunks' of HTML in the answers
(to the goals). This process is shown in Figure 4.
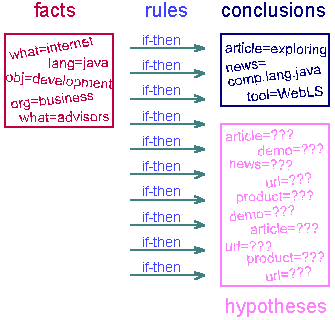
Initially, we get some facts when the user answers the first set of
questions. These facts are processed by the rules, which result in some
of the rules being proven (conclusions), and many rules as hypotheses for
which additional information is required.
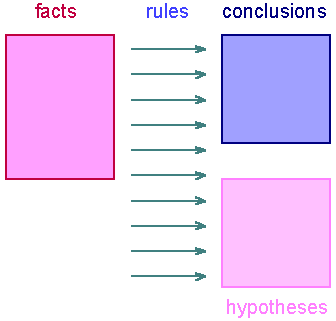
As the inference engine continues to run, the number of facts and rules
that have been proven (conclusions) increase, while the number of rules
left to prove (hypotheses) declines.
After each set of questions is answered this process continues, the
number of facts and conclusions increase and the hypotheses decrease.
Finally, all the rules have been proven or disproven and we are left
with a set of facts and a set of conclusions or answers which are used
to assemble the output document.
Figure 4
Grouping Questions
One of the biggest challenges in WebLS is how to ask the questions. More
traditional expert systems simply ask the question when the value is needed.
But this is tedious and inefficient over the web. So we made a number of
efforts for grouping questions together.
First Attempt: By Rules
Our first attempt was to allow rules on questions that would control when
they are asked. For example, 'biopsy type' would be asked only if 'biopsy
performed' was 'yes', as there is no need to ask the biopsy type if none
was performed yet.
Unfortunately this deviated from our keep-it-simple philosophy, and
our domain expert started coding knowledge in the rules for questions,
instead of writing more complete rules. This led to an incomprehensible
inferencing mechanism and logic-bases that were impossible to debug.
Second Attempt: By Ask After and Ordering
Our second attempt, which seems to work very well, is to simply have an
optional 'ask after' list for a question. In this case, given the list
of questions to ask, WebLS eliminates the questions that need to be asked
after other questions. For example, 'biopsy type' would have an 'ask after'
of 'biopsy performed'. When WebLS has both questions on its list to ask,
'biopsy type' will be delayed until 'biopsy performed' has been answered.
To give precise control over the ordering of questions, we also use
an optional priority number in the questions. This results in ordering
the questions on the output page.
Saving the Inferencing State Across Web Forms and Sessions
Web applications run in a unique manner. They are started up each time
the user submits a form or presses a button. Hence, WebLS is being invoked
by multiple users simultaneously.
Some mechanism is needed to save the facts as each set of questions
is being asked. This is simply done by using hidden form fields. So when
a web form is submitted by the user, that form contains all the new responses
plus all the previous responses. Of course, this also means the WebLS inference
engine starts 'from the top' each time it is invoked. This has not proven
to be a performance problem, however, should it become so, intermediate
facts could also be saved in hidden form fields.
As the decision guide consists of many modules which may be consulted
over a period of months or years, it is further desirable to save the facts
across BCPath sessions. This is accomplished by writing them to a cookie,
which is saved in the user's web browser. This approach was chosen to protect
the user's privacy under U.S. government regulations.
Nice Touches
Displaying/Clearing Current Facts
WebLS includes the ability to display the currently saved cookie facts,
and to allow the user to selectively delete particular responses. The practical
result of this is the next time a consultation is run, those questions
will be asked again.
Displaying Citations and Advanced Information
As the output document consists of many chunks of information, an 'advanced'
section was added to the ALMs. This section is also an HTML chunk, but
contains more detailed or more difficult information. The user can click
on a special icon to see the additional information that pertains to a
particular 'chunk'.
In addition, the user can review the citations corresponding to a 'chunk'
of information. Of course, these are displayed directly from the human-readable
part of the ALMs.
Conclusions and Future Work
As of this writing, the system has been reviewed by breast cancer caregivers,
support organizations, survivors, senior military officers, doctors and
specialists, and is nearing the end of its phase 1 funding. We are currently
systematically vetting and editing the knowledgebase information in order
to beta test the diagnosis module with new breast cancer patients within
the Department of Defense. There is also a significant amount of knowledge
completed for the treatment section, as well as some work in coping and
DoD specific issues.
The review and testing to date has indicated the need for the following
features.
Multiple Views of the Selected 'Chunks'
WebLS currently implements one 'view' of the information selected by the
rules during inferencing, that is, the document in outline form. As the
number of 'chunks' selected increases, additional views are needed. One
such view would allow the display of 'chunks' that pertain to one or more
keywords. Other views might group 'chunks' that emanate from the same source.
Making Everything Objects
The next logical step with ALMs is to turn them into proper objects that
are stored in a database. Also, all pictures, videos, sounds and external
URLs need to be made into objects so they can be readily maintained. This
architecture is shown below:
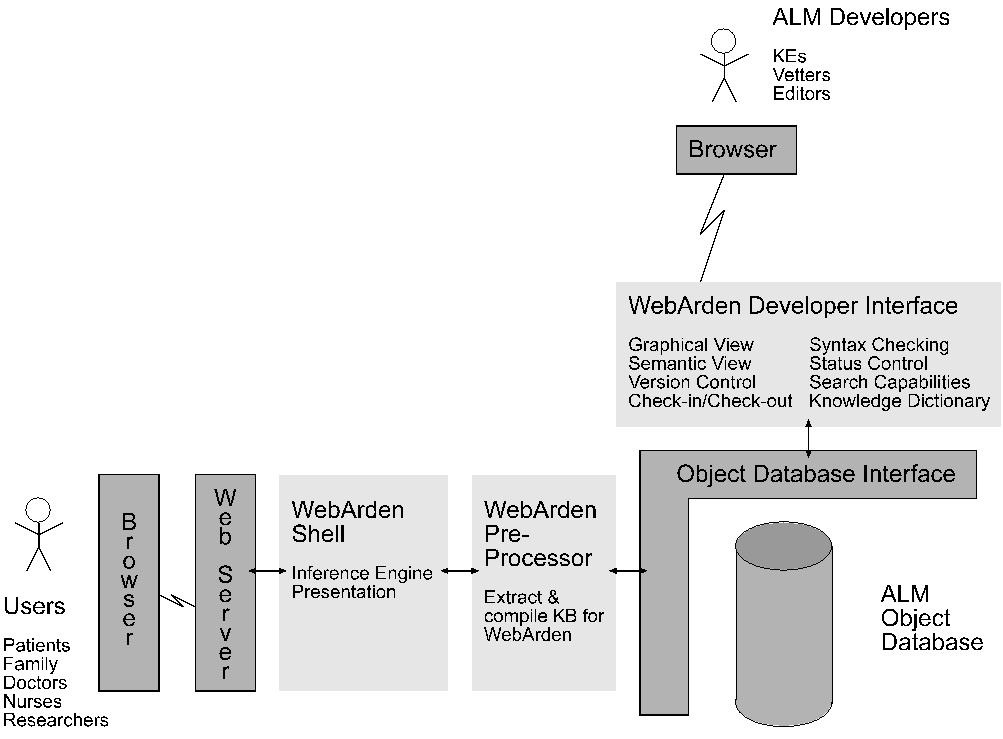
Figure 5: In the future ALMs will become true objects and will be
stored in a database. The developer's interface will expand greatly to
give both graphical and semantic views of the ALMs, as well as all the
tools needed to manage their creation and editing in a multi-user, web-based
environment.
Project Group Development Tools
To support the view of ALMs as objects, web-based tools need to be created
for the ALM developer. These tools allow ALMs to be checked-in and out
of the database. They can also find ALMs, perform syntax and semantic checks
and provide various views of the database.
These tools are needed as the next phase of BCPath development will
require multiple domain experts, as well as editors (for consistent language
use) and vetters (to ensure medically correct content).
Bibliography
[Kroening, 96] Kroening, M. 1996 "Automating Tech Support", Dr. Dobb's
Sourcebook, Sep/Oct 96
[Merritt, 96] Merritt, D. 1996, "Building Custom Rule Engines", PC AI,
Mar/Apr 96.
[Sehmi, 96] Sehmi, A., Kroening M., 1996, "WebLS: A Custom Prolog Rule
Engine for Providing Web-Based Tech Support", 1st Workshop on Logic Programming
Tools for INTERNET Applications, JICSLP '96
If you are interested in seeing the in-development BCPath system,
please e-mail Sabina Robinson at srobsaic@telerama.lm.com. For more information
about WebLS, and the Amzi! Prolog + Logic Server technology, please e-mail
Mary Kroening through www.amzi.com. This work was funded by the U.S. Army Medical
Research and Materiel Command under contract DAMD17-93-C-3141.